
4.3 性能
写关于 JavaScript 性能的文章是件棘手的事,因为它是一个不断变化的目标。浏览器实现会定期改进,目前运行缓慢的代码可能很快就会被优化。然而,即使在自更新浏览器不断演进的情况下,仍然存在一套通用的最佳实践和禁忌,它们通常适用,并且不太可能发生改变。
讨论 JavaScript 性能时,我们必须承认它会因浏览器而异。每种 JavaScript 引擎都有其优势和劣势,性能特性可能因使用的功能不同而产生巨大差异。像 jsPerf.com 这样的网站应运而生,专门用于比较各种浏览器的性能,通常以特定语言或库功能的微基准测试(microbenchmark)形式呈现。尽管 jsPerf 可能有一定的参考价值,但我们更推荐一种更直接的方法。所有现代浏览器都在其强大的调试环境中内置了出色的性能分析工具。无论是 Chrome、Firefox、Internet Explorer 还是 Safari,我们发现确定性能瓶颈最简单的方法就是直接启用性能分析器运行代码。
然而,并非所有的性能问题都会在性能分析器中显现出来。一些语言特性或架构设计可能会带来隐藏的性能成本,并分布在整个代码库中。应对这些问题的最佳方式是遵循我们在这里列出的最佳实践,并且时刻关注 JavaScript 引擎不断变化的发展趋势。
4.3.1 对象的定义与构造
一些最基本的 JavaScript 引擎优化依赖于获取类型信息。不幸的是,由于 JavaScript 是一种动态类型语言,这些信息并不容易获得。大多数引擎使用一种称为 类型推断(type inferencing) 的技术,在运行时从代码中推断类型。我们的 JavaScript 代码越是表现得像静态类型语言, 引擎优化它就越容易。例如,考虑以下 Cartesian3 构造函数:
var Cartesian3 = function (x, y, z) {
this.x = x;
this.y = y;
this.z = z;
};
稍后,我们可能需要给某个 Cartesian3 实例添加一个 w 属性。在 JavaScript 中,可以简单地使用 instance.w = 1 来动态添加属性,这可能很诱人。然而,这种做法并不推荐,因为它可能会对性能产生负面影响。
在静态类型语言中,我们根本无法动态地为 Cartesian3 类的单个实例添加 w 属性。相反,我们必须定义一个新的类,并创建一个新的实例,同时将 x、y 和 z 的值复制到新实例中。尽管现代 JavaScript 运行时引擎有很多优化技巧,但它们最终还是会生成类似于静态类型语言编译后的机器代码指令。
当我们像之前那样定义 Cartesian3 构造函数时,许多 JavaScript 虚拟机(VM)会创建一个内部的类型表示,以加速属性访问和方法调用,并使其在内存中的表示尽可能高效。理想情况下,Cartesian3 在内存中会被表示为三个浮点数,尽管即使在最先进的 JavaScript 引擎中,可能仍然会有一些额外的开销。如果 Cartesian3 实例的内存布局经过优化,那么添加 w 属性的成本就会非常高。JavaScript 引擎可能不得不重新分配该实例,并复制已有的属性,就像我们在静态类型语言中手动执行的那样。最终,引擎可能会选择为这个新添加属性的实例使用一种效率较低的数据结构。
此外,当 JavaScript 引擎为一个接受 Cartesian3 实例作为参数的函数生成机器代码时,它可能会针对该类型创建一个优化版本。例如,许多引擎使用 内联缓存(inline caching),将方法和属性查找的结果存储在生成的代码中。但如果 Cartesian3 的实例发生结构性变化(比如添加 w 属性),那么这些缓存就会失效。引擎将不得不生成新的代码,或者更可能的是,回退到未优化的代码路径,并使用 栈上替换(on-stack replacement, OSR)。
更好的解决方案是,直接定义一个 Cartesian4 构造函数,并从一开始就包含 w 属性。然后,在需要时使用 Cartesian4 的实例。这种方式能够为 JavaScript 引擎提供最多的类型信息,并且使其能够生成更快的代码。总的来说,如果某个操作在静态类型语言中执行起来困难或缓慢,那么在 JavaScript 中它几乎肯定也是低效的。
JavaScript 提供了多种定义和构造对象的方法,但像之前那样使用 构造函数(constructor function) 仍然是最快的方式。根据我们的基准测试,Object.create 的性能比 new 关键字慢 3 到 5 倍,但过去情况更糟。对象字面量(object literal) 的速度几乎和 new 关键字一样快,但前提是我们要在父作用域中缓存方法,以避免在每次创建对象时都重新定义它们。需要注意的是,这些测试基于微基准测试(microbenchmarks),因此可能不会完全反映实际应用的性能情况。因此,与其纠结于对象创建的开销,不如采用更好的解决方案 —— 完全避免分配(allocation),这将在 4.3.2 节 中讨论。
与对象构造方式类似,我们定义对象属性的方法 也会对整体性能产生重大影响。虽然某些 JavaScript 引擎会内联简单的 getter 和 setter 方法,但在某些浏览器中,函数调用的开销仍然足够显著,需要我们考虑。这意味着,如果我们希望在对象上公开一个属性,直接将其暴露为公共字段(public field) 会比使用 get 和 set 方法更快。此外,虽然 Object.defineProperty 允许我们创建类似于 C# 等语言中的现代属性,但在某些浏览器上,它的开销与函数调用相当。
在 Cesium 中,我们遵循一个简单的规则:
- 如果某个属性通常在其他语言中只是一个简单的 getter 或 setter,我们就直接暴露它。
- 如果属性的 getter 或 setter 需要执行额外的逻辑,我们才会使用
Object.defineProperty。
通过直接暴露属性,这不仅可以保持 API 的一致性,还可以最大程度地减少运行时开销。
4.3.2 垃圾回收开销
在许多高性能 JavaScript 应用程序中,垃圾回收(GC)是一个主要问题,而 3D 应用程序的特性使这个问题变得更加严重。例如,假设我们需要对场景中的每个对象执行两个向量的乘法计算。如果场景中有 10,000 个对象,并且目标帧率是 60 帧每秒,那么我们每秒就会创建 120,000 个向量结果对象。在 C++ 或 C# 等语言中,这通常不会成为问题,因为向量很可能会被分配在栈上。然而,在 JavaScript 中,这种对象的频繁创建和销毁可能会成为性能瓶颈。
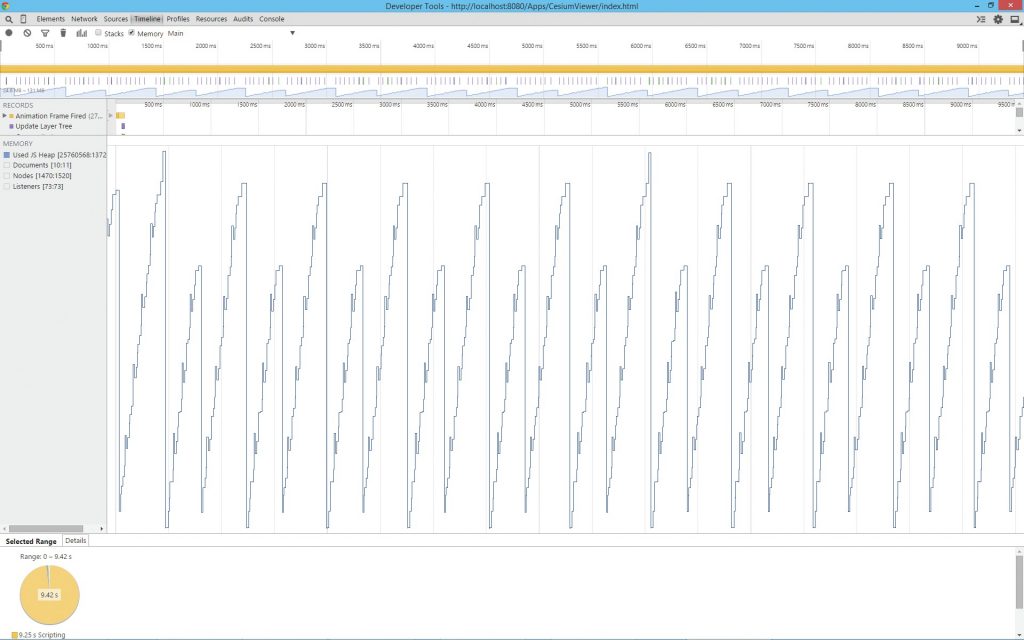
在 WebGL 应用程序中,类似的数学运算是不可避免的。在 Cesium 早期开发阶段,我们经常在性能分析中发现,代码运行时间的 50% 竟然消耗在垃圾回收上。浏览器的性能分析工具会以“锯齿”模式显示这一问题,如 图 4.2 所示。图中的峰值代表垃圾回收的触发时刻,在这些时刻,垃圾回收器会释放内存,但同时也会占用本应属于代码执行的宝贵处理时间。
这种不必要的 内存抖动(memory churn)通常是由计算 中间值(intermediate values)导致的,这些值在计算完成后会被立即丢弃。例如,代码示例 4.7 展示了 Cesium 的 Cartesian3 线性插值(linear interpolation)实现的简化版本,该实现中就可能出现大量临时对象的创建和销毁。
Cartesian3.add = function (left, right) {
var x = left.x + right.x;
var y = left.y + right.y;
var z = left.z + right.z;
return new Cartesian3(x, y, z);
};
Cartesian3.multiplyByScalar = function (value, scalar) {
var x = value.x * scalar;
var y = value.y * scalar;
var z = value.z * scalar;
return new Cartesian3(x, y, z);
};
Cartesian3.lerp = function (start, end, t) {
var tmp = Cartesian3.multiplyByScalar(end, t);
var tmp2 = Cartesian3.multiplyByScalar(start, 1.0 - t);
return Cartesian3.add(tmp, tmp2);
};
每次调用 lerp 都会分配三个对象:两个中间的 Cartesian3 实例和一个结果实例。虽然在 Firefox 中运行 100,000 次的微基准测试大约需要 9.0 毫秒,但这并不会暴露垃圾回收的问题,因为内存清理通常发生在基准测试完成之后。
我们可以通过两种简单的技术来消除额外的内存分配。首先,我们要求用户传入一个已分配的 result 参数,以避免每次调用都创建新的实例。其次,我们在 lerp 内部调用 add 时,使用模块范围的临时变量(scratch parameters)。
Cartesian3.add = function (left, right, result) {
result.x = left.x + right.x;
result.y = left.y + right.y;
result.z = left.z + right.z;
return result;
};
Cartesian3.multiplyByScalar = function (value, scalar) {
result.x = value.x * scalar;
result.y = value.y * scalar;
result.z = value.z * scalar;
return result;
};
var tmp = new Cartesian3(0, 0, 0);
var tmp2 = new Cartesian3(0, 0, 0);
Cartesian3.lerp = function (start, end, t, result) {
Cartesian3.multiplyByScalar(end, t, tmp);
Cartesian3.multiplyByScalar(start, 1.0 - t, tmp2);
return Cartesian3.add(tmp, tmp2, result);
};
修改后的实现在加载时初始化了两个临时变量,但除此之外不会再分配额外的内存。虽然在 Firefox 中 100,000 次调用这个版本的 lerp 仅需 6 毫秒(很可能是因为减少了对象创建),但在所有浏览器中它并不一定都更快。真正的提升体现在整个应用的性能分析中,我们可以观察到垃圾回收时间在性能分析工具中大幅减少,从而提高了帧率。
在 Cesium 中,每帧可能会调用超过 100,000 次这样的函数。使用 result 参数和临时变量能帮助我们在每帧的计算预算中节省几毫秒。尽管我们不喜欢这样做会让代码和 API 变得复杂,但对于任何希望编写高性能、复杂的 WebGL 应用的人来说,result 参数是绝对必要的。
4.3.3 Web Workers 的隐形成本及如何避免它
在 Cesium 中,我们允许用户定义的几何体(如椭球体、多边形、盒子和圆柱体)可以在主线程上同步计算,也可以通过 Web Workers 在后台线程中异步计算。然而,我们最初的 Web Worker 实现竟然比单线程版本慢了好几个数量级,这让我们大吃一惊。事实证明,当在不同线程之间传递大量数据时,Web Workers 存在一个隐藏的性能开销。
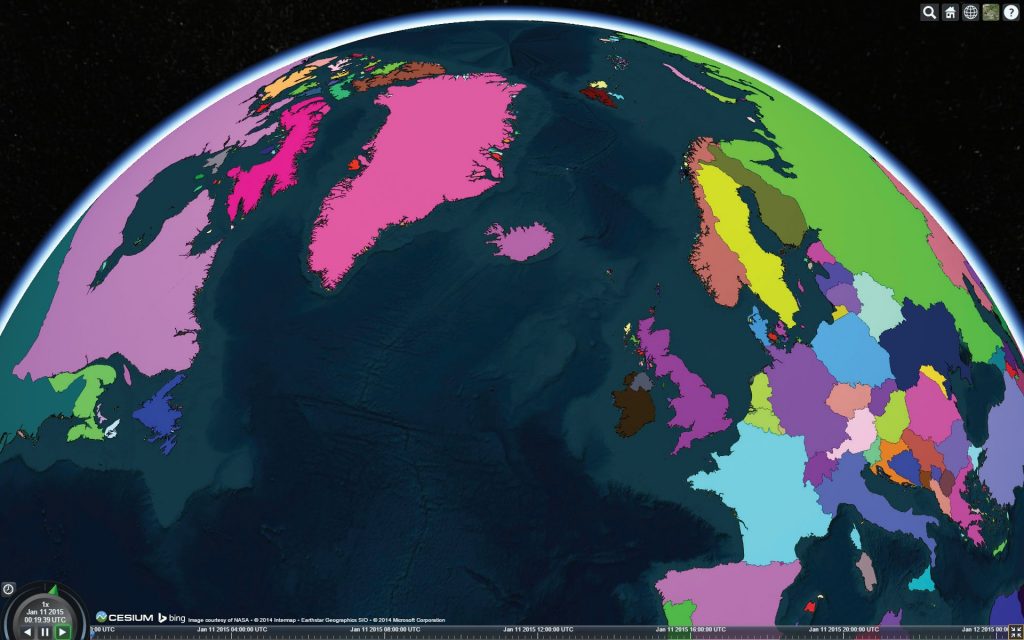
为了说明这个问题,假设我们只处理多边形。多边形三角化是一个 CPU 密集型任务,将其卸载到工作线程可以防止应用程序在处理时出现卡顿。而且,包含 50 万多个顶点的多边形组并不罕见,比如图 4.3 所示的国家边界数据。
由于 JavaScript 传统上是单线程语言,因此使用 Web Workers 与传统 API 有很大不同。Worker 无法访问 DOM,并且在与主线程不同的全局上下文中执行代码。
主线程和 Worker 之间的消息和数据总是通过拷贝来传递的,因为它们不共享内存或任何其他可变状态。HTML5 规范定义了一种用于复制 Worker 消息的算法,称为结构化克隆(structured clone)。在结构化克隆过程中,被拷贝的对象会丢失所有原型和函数信息,因此如果需要,接收线程必须重新构造这些信息。结构化克隆的过程大致相当于将对象序列化为 JSON 并在接收端进行反序列化。
有一种方法可以避免在将数据传递给 Web Worker 时进行拷贝,那就是使用可转移对象(Transferable)。顾名思义,Transferable 对象可以被转移(而不是拷贝)到 Worker 线程。一旦对象被转移,它将成为接收 Worker 的专有属性,发送方将无法再访问它。这样,我们既避免了共享数据,也避免了数据拷贝。然而,遗憾的是,我们无法让自定义对象成为 Transferable 对象。目前,规范中仅有两种 Transferable 对象:ArrayBuffer 和 MessagePort。
对于我们的使用场景,克隆操作在所有浏览器中的性能都极其低下。这是可以理解的,因为结构化克隆是一种通用算法,设计用于拷贝几乎任何对象。但是,它到底有多慢呢?假设我们创建一个 Web Worker,仅仅是将接收到的数据再传回主线程。如果传递的是 ArrayBuffer,它会被直接转移,而其他类型的数据都会被正常拷贝。执行该 Worker 并接收返回数据所花费的时间,几乎完全取决于结构化克隆的开销,并且该开销会被放大两倍(数据需要从主线程发送到 Worker,再从 Worker 返回主线程)。
//contents of worker.js
var onmessage = function (e) {
postMessage(e.data, e.data.buffer ? [e.data.buffer] : undefined);
};
//code to spawn worker.js
function timeWorker(data) {
var worker = new Worker("worker.js");
var start = performance.now();
worker.addEventListener("message", function (e) {
console.log(performance.now() - start);
worker.terminate();
}, false);
worker.postMessage(data);
}
在我们的测试中,使用包含 500,000 个 Cartesian3 实例的数组执行上述代码,平均需要 3.8 到 6.2 秒(不是毫秒!)才能完成,具体时间取决于所使用的浏览器。更糟糕的是,由于向 Web Worker 发送数据和从 Worker 接收数据是同步的,这一过程的一半时间都会导致页面卡死,无法响应用户输入。事后看来,这个结果并不意外,但当我们第一次遇到它时,仍然感到很沮丧。在许多情况下,将数据发送到 Web Worker 的开销比直接在主线程同步执行任务并造成页面卡顿还要严重。我们认为一定有更好的解决方案。
正如我们之前提到的,ArrayBuffer 是可以无拷贝地传输到 Worker 线程的对象之一。如果我们手动将数据打包到一个 TypedArray 并传输到 Worker,会不会比浏览器在原生代码中执行的结构化克隆(structured clone)更快呢?Worker 仍然需要解包数据,并且打包和解包代码需要针对传递给 Worker 的参数进行特定处理,但我们觉得值得一试。下面是修改后的代码,以及两个用于打包和解包 Cartesian3 实例数组的辅助函数:
function packCartesian3Array(data) {
var j = 0;
var packedData = new Float64Array(data.length * 3);
for (var i = 0, len = data.length; i < len; i++) {
var item = data[i];
packedData[j++] = item.x;
packedData[j++] = item.y;
packedData[j++] = item.z;
}
return packedData;
}
function unpackCartesian3Array(packedData) {
var j = 0;
var data = new Array(packedData.length / 3);
for (var i = 0; i < packedData.length; i++) {
var x = packedData[j++];
var y = packedData[j++];
var z = packedData[j++];
data[i] = new Cartesian3(x, y, z);
}
return data;
}
function timeWorker(data) {
var packedWorker = new Worker("worker.js");
var start = performance.now();
var packedData = packCartesian3Array(data);
packedWorker.addEventListener("message", function (e) {
var receivedData = unpackCartesian3Array(e.data);
console.log(performance.now() - start);
packedWorker.terminate();
}, false);
packedWorker.postMessage(packedData, [packedData.buffer]);
}
最终的结果令人惊喜。手动打包版本的速度远远快于依赖默认的克隆操作,完成任务的平均时间仅为 60 到 600 毫秒。尽管需要手动维护,但这种技术允许我们将所有对象及其属性(包括字符串)打包到一个单一的 TypedArray 中,以实现高效传输。
4.3.4 最大化利用多核处理能力
在多线程编程中,一个常见的技术是使用尽可能多的线程与可用 CPU 核心数匹配,以实现最大程度的并行化。如果线程数量过多,频繁的上下文切换会导致性能下降;如果线程过少,则会浪费空闲的 CPU 核心。不幸的是,JavaScript 没有官方标准来访问系统的核心数量,我们认为这是一个重大缺陷,极大地限制了 Web Workers 的实际效用。
值得庆幸的是,一些浏览器最近新增了一个非标准属性 navigator.hardwareConcurrency,用于暴露客户端系统上的逻辑处理器数量。尽管目前仅在 Chrome、Opera 和 Safari 中受支持,但它仍然是一个非常有用的特性,值得一提。虽然 Firefox 和 IE 目前尚未实现该属性,但可以使用 shim 进行兼容。
4.4 WebGL 应用的自动化测试
我们认为,自动化测试对于任何严肃的应用程序来说都是至关重要的。一个良好的自动化测试套件能够帮助我们深入验证代码是否正常运行,因为它可以覆盖边界情况和不常见的代码路径。此外,它还能够显著提升我们对代码重构的信心,而这对于一个具有多年开发计划的应用来说尤为重要。
虽然这在任何编程语言的应用中都是成立的,但 JavaScript 还需要额外考虑一些因素。Web 浏览器对于错误的 JavaScript 代码往往非常宽容。例如,我们可以编写一个包含语法错误的 JavaScript 函数,浏览器在执行该函数之前可能不会报错。同样,一个简单的拼写错误(可能出现在错误处理代码中)也很可能在没有执行到该代码路径的情况下完全不被发现。因此,自动化测试结合良好的代码覆盖率,是确保所有代码正确执行并符合预期行为的最佳工具。
目前有大量的 JavaScript 测试框架和测试运行器可供选择,每个框架都附带一张比较表,试图证明自己是最好的。在 Cesium 中,我们最终选择了 Jasmine 作为测试框架,Karma 作为测试运行器。
4.4.1 Jasmine
在某些方面,Jasmine 可以说是“老派”的。它不使用模块系统,而是通过 <script> 标签引入,并将其函数添加到全局作用域。此外,它的功能也不是特别丰富。然而,它的优势在于提供了简洁优雅的测试语法,而且由于其简单性,使其能够轻松集成到各种不同类型的应用程序中。例如,我们成功地在基于 AMD 和 CommonJS / Browserify 的应用程序中使用了 Jasmine。
Jasmine 是一个行为驱动开发(BDD)框架,这意味着我们编写的测试风格更像是在用英语描述代码的预期行为。例如:
describe('Cartesian3', function () {
it('normalizes to a vector with magnitude 1', function () {
var original = new Cartesian3(1.0, 2.0, 3.0);
var normalized = Cartesian3.normalize(original);
var magnitude = Cartesian3.magnitude(normalized);
expect(magnitude).toEqual(1.0);
});
});
在浏览器中运行 Jasmine 测试(在 Jasmine 中称为 specs)需要我们设置一个 SpecRunner.html 文件,可以使用 Jasmine 发行包中提供的模板作为起点(见 图 4.4)。SpecRunner 的具体设置取决于应用程序的结构。但无论如何,我们都需要使用标准的 <script> 标签引入 Jasmine 的相关脚本。而实际运行测试用例的方式,则取决于项目的架构。
如果我们不使用模块系统,那么测试的设置虽然比较直接,但对于大型应用来说会非常痛苦:我们需要在 SpecRunner.html 中按照正确的顺序,手动添加所有 源代码文件 和 测试文件 的 <script> 标签。
如果我们使用 CommonJS 模块,并通过 Browserify 构建出一个单一的 JavaScript 文件,该文件包含所有的测试用例及其依赖项,那么测试就变得简单了:我们只需要在 SpecRunner.html 中添加一个 <script> 标签,引用构建后的 JavaScript 文件即可。
对于 AMD(Asynchronous Module Definition,异步模块定义),情况则要复杂一些,因为 AMD 是异步的。默认情况下,Jasmine 会在 window.onload 事件触发时运行所有已知的测试。然而,在使用 AMD 时,测试模块在 window.onload 触发时可能尚未加载完毕。因此,我们需要手动加载所有的 spec 模块,并确保在所有模块都加载完成后再启动 Jasmine。首先,在 SpecRunner.html 中添加一个 RequireJS 的 <script> 标签,并使用 data-main 属性指定测试入口模块:
<!-- SpecRunner.html --> <script data-main="specs/spec-main" src="../requirejs-2.1.9/require.js"></script>
然后,在 spec-main 模块中,require 所有的 spec 模块,并执行 Jasmine 环境:
//spec-main.js
define([
'./Cartesian3Spec',
'./Matrix4Spec',
'./RaySpec'
], function () {
var env = jasmine.getEnv();
env.execute();
});
在 spec-main 函数中,我们实际上不需要对每个 spec 模块传递参数,因为我们不需要使用这些参数,我们只是确保这些模块能够被正确加载。
当然,手动维护这些 spec 模块的列表是比较麻烦的,但由于 Web 浏览器无法直接读取本地文件系统来自动获取 spec 列表,因此我们必须通过某种方式来指定完整的 spec 文件列表。在 Cesium 中,我们使用了一个简单的构建步骤,自动生成完整的 spec 模块列表,以避免手动维护这些列表的麻烦。
当 SpecRunner.html 配置完成后,我们只需要使用任何 Web 服务器 进行托管,然后在任意浏览器中访问它,即可运行测试。
4.4.2 Karma
在 Jasmine 中运行测试是一个手动的过程。我们需要打开一个 Web 浏览器,访问 SpecRunner.html 文件,等待测试执行完成,并检查是否有测试失败。Karma 让我们可以自动化这一过程。
使用 Karma,只需一个命令就可以启动系统中的所有浏览器,在每个浏览器中运行测试,并在命令行中报告测试结果。这对 持续集成(CI) 过程至关重要,因为它可以让浏览器中的测试失败转化为构建过程的失败。此外,Karma 还可以监视代码变更,并在检测到变化时自动重新运行测试,这对测试驱动开发(TDD) 或构建测试套件时非常有用。
与 Jasmine 相比,Karma 的设置相对简单,即使是用于 AMD 模块也不会太麻烦。首先,我们需要在 Node.js 环境中使用 npm 安装 Karma,然后运行以下命令,交互式地生成 Karma 的配置文件:
karma init
Karma 内置支持 Jasmine 以及其他多个测试框架,并且可以通过插件扩展支持更多框架。配置完成后,我们可以使用以下命令在所有已配置的浏览器中运行测试:
karma start
4.4.3 测试 WebGL 代码
目前讨论的内容适用于几乎所有 JavaScript 应用的测试。但 WebGL 代码的测试有哪些独特的挑战呢?
实际上,我们可以在不真正渲染图像的情况下,测试大部分图形代码。例如,我们可以使用标准的单元测试来验证三角剖分、细分、批处理以及不同层级细节(LOD)选择等算法,确保它们生成的数据结构和数值正确。然而,部分渲染代码不可避免地需要直接调用 WebGL API,即使这部分代码很少。
有些人可能会坚持认为:单元测试不应该直接调用 WebGL API,而是应该调用一个可测试的抽象层,例如模拟(mock)和存根(stub)。在这种理想情况下,测试 WebGL 应用和测试普通应用没有区别——测试代码仅检查是否调用了正确的 WebGL 函数,而不真正执行这些函数。
虽然我们认可这种方法的价值,但我们也认为实际的 WebGL 应用最终都需要超越这种方式。原因如下:
- WebGL API 太复杂,如果我们只是模拟 WebGL 而不进行真实测试,我们很难确保代码在真实环境下能够正确运行。
- WebGL 在不同浏览器和 GPU 组合上的行为可能不同,单纯的模拟无法覆盖所有情况。我们可以把这些测试称为集成测试而不是单元测试,但它们仍然是测试体系中重要的一部分。
- 完全模拟 WebGL API 代价高昂,实现一个足够完善的 WebGL Mock 或 Stub 需要大量的工作。
在之前的讨论中,我们刻意回避了诸如 Sauce Labs 之类的云端 JavaScript 测试解决方案。原因是:截至目前,这些云测试平台并不可靠地支持 WebGL。这让我们感到遗憾,因为如果 WebGL 云测试可行,我们就能在不同操作系统和浏览器上运行测试,而无需维护自己的测试基础设施。但目前的问题是:这些云测试平台依赖虚拟化技术,而虚拟环境中的 GPU 硬件加速仍处于早期阶段,支持不稳定;由于 WebGL 需要直接访问 GPU 硬件,而虚拟机通常无法完全访问底层 GPU 资源,这导致测试结果无法准确反映真实环境。因此,我们当前的方法是:使用 Karma 在物理设备上运行 WebGL 测试,并将其整合到 CI 流程中。
在 WebGL 应用中,数百或数千行代码共同作用,以在屏幕上绘制特定的像素模式。那么,我们如何编写自动化测试来确认这些像素模式是否正确?
没有简单的答案。在以往的项目中,我们采用了一种方式:渲染场景 → 截屏 → 将结果与“已知正确”截图进行对比。但这带来了严重的问题:
- GPU、驱动版本的不同会导致截图不一致,即使代码是正确的。
- 当测试失败时,我们往往怀疑:问题是出在驱动?操作系统?测试环境?而不是代码本身。
- 我们尝试过模糊匹配(即允许一定误差),但这仍然是一个不断调整“误差阈值”的痛苦过程。
- 不同硬件上的测试结果不可预测,即使 WebGL 代码完全正确,也可能因为驱动或 GPU 差异而导致测试失败。
最终,我们不推荐这种“截图比对”方法。
其他团队报告了一种更可靠的方法:针对每种平台、GPU、驱动,维护一组“已知正确”截图,并人工校验。虽然这种方法有效,但成本极高,需要大量维护工作。Cesium 采取了一种更简单的策略:渲染单个像素,并断言该像素的颜色是否正确。例如,以下是一个简化的测试,用于验证一个多边形是否正确渲染:
it('renders', function () {
var gl = createContext();
setupCamera(gl);
drawPolygon(gl);
var pixels = new Uint8Array(4);
gl.readPixels(0, 0, 1, 1, gl.RGBA, gl.UNSIGNED_BYTE, pixels);
expect(pixels).not.toEqual([0, 0, 0, 0]);
destroyContext(context);
});
这个测试仅仅断言该像素不是黑色,这也是 Cesium 进行单像素渲染测试的典型方式。有时,我们可能会检查更具体的内容,比如红色通道不为零或者完全白色。不过,我们通常不会检查精确的颜色值,因为不同浏览器和 GPU 之间的差异可能会导致该测试变得不可靠。
在前面的示例中,每个测试都会创建一个独立的 WebGL 上下文(context),但在 Cesium 的测试中,我们尽量避免这样做。原因如下:
- 创建 WebGL 上下文的开销较大,初始化和设置需要时间,而我们希望测试尽可能快速执行。
- 浏览器并不期望应用程序频繁创建和销毁大量 WebGL 上下文。我们曾在多个浏览器中遇到过Bug,当测试中途频繁创建 WebGL 上下文时,创建操作会开始失败。
- 但如果所有测试共用同一个 WebGL 上下文,则可能导致某个测试破坏上下文状态,从而影响后续测试的正确性。
在 Cesium 的测试中,我们找到了一种折中方案:为每个测试套件(test suite)创建一个 WebGL 上下文。测试套件通常是一个独立的源文件,用于测试某个特定的功能模块(比如某个类),这样我们可以更容易地理解 WebGL 上下文状态的变化。
当然,单像素渲染测试远不能覆盖所有情况。这个测试只是断言多边形在屏幕上绘制了某些内容,但仍有许多可能的错误不会导致该测试失败。不过,反过来却是成立的:如果多边形、WebGL 栈和 GPU 驱动都正常工作,那么这个测试“不应该”失败。
4.4.4 测试着色器
Cesium 维护了一套可复用的 GLSL 函数库,用于顶点着色器(Vertex Shader)和片元着色器(Fragment Shader)。其中一些函数相当复杂,比如:计算射线与椭球的交点,将大地纬度(Geodetic Latitude)转换为 Web Mercator 坐标(Web 地图中常用的投影)。我们认为,对这些 GLSL 着色器函数进行单元测试,与测试 JavaScript 函数一样重要。然而,Jasmine 不能在 GPU 上运行,那么我们该如何测试这些着色器呢?
我们的方法非常直接:编写一个片元着色器(Fragment Shader),调用需要测试的 GLSL 函数。检查期望的条件,如果测试通过,则输出白色(gl_FragColor = 白色)。举个例子,假设我们要测试 czm_transpose 函数(一个 2×2 矩阵转置函数),那么测试着色器可能如下:
void main() {
mat2 m = mat2(1.0, 2.0, 3.0, 4.0);
mat2 mt = mat2(1.0, 3.0, 2.0, 4.0);
gl_FragColor=vec4(czm_transpose(m)==mt);
}
当 czm_transpose 正确计算矩阵转置时,片元着色器(Fragment Shader) 会将 gl_FragColor 设为白色。如果计算错误,则 gl_FragColor 会变成透明黑色。
然后,我们在Jasmine 中调用这个测试着色器:绘制一个单点,使用简单的顶点着色器(Vertex Shader)和上述片元着色器。使用 gl.readPixels 读取像素值,断言其是否为白色。
我们发现这是一种简单、轻量且有效的着色器函数测试方法。然而,这种方式无法测试完整的顶点着色器或片元着色器,也不适用于在单个测试中断言多个条件。如果需要这些功能,可以考虑使用更全面的 GLSL 测试工具,如 GLSL Unit。
然而,对于 Cesium 来说,我们发现没有必要使用复杂的 GLSL 测试工具。通过测试着色器的基本构建块(即单个函数),并尽可能保持 main() 函数的简单性,我们就能够对着色器的正确性充满信心,而无需复杂的 GLSL 测试流程。
4.4.5 测试很难
在 Cesium 中,我们有几种类型的测试:
- 基础算法测试:验证算法生成的数据结构和数值,这些测试不涉及任何渲染。
- 渲染冒烟测试(详见 4.4.3 节):通常渲染单个像素并验证其结果是否合理。有时我们也会渲染完整场景,并仅验证渲染过程中是否抛出异常。
- 着色器函数测试(详见 4.4.4 节):测试构成着色器的可复用函数,通过在测试片段着色器中调用它们,并断言输出是否为白色。
我们发现,这些类型的测试相对容易编写,稳定性高,并且值得投入时间去实现。
然而,我们无法完全避免需要真人在不同系统和浏览器上运行应用,以确保最终渲染的输出符合预期。