
3D Gaussian Splatting(3DGS)正在快速成为 Web 端实景三维渲染的主流表示方式。但”如何在浏览器里高效地流式加载并渲染数百万甚至上千万个 splat”,目前业界并没有统一答案。本文对比当前两条最具代表性的开源技术路线——Cesium 3D Tiles + glTF KHR_gaussian_splatting 与 SparkJS 2.0——从数据格式、LOD 策略、流式管线、运行时内存到生态适配,逐层拆解它们的设计哲学与取舍。
Cesium 和 SparkJS 在用相反的思路解决同一个问题:
- Cesium 把高斯泼溅当作 3D Tiles 体系里的一种标准 payload:3D Tiles 负责空间索引、metadata 和请求模型,glTF 扩展
KHR_gaussian_splatting定义 splat 数据的语义,当前实现还要求配套 SPZ 压缩扩展。 - SparkJS 2.0 把高斯泼溅当作渲染器原生的数据结构:用自定义 Gaussian tree 做 LOD,用固定的全局 splat budget 控制开销,用 GPU 上的虚拟化页表管理驻留,用自有的
.rad格式做分块流式加载。
简单来说:需要开放标准、georeferencing、3D Tiles metadata、与大型地理空间场景集成,选 Cesium;需要严格控制运行时 splat 数量、细粒度分页、低活跃内存、与 Three.js 应用紧密集成,选 SparkJS。
架构与数据格式
Cesium:标准分层堆栈
Cesium 的架构是一个分层堆栈。最外层是 3D Tiles tileset:每个 tile 有 bounding volume、geometric error、refinement mode 和 content URI。使用 implicit tiling 时,层级结构由 subtree 文件索引,availability bitstream 按 Morton 顺序排列,还可以通过 property table 挂 metadata。
每个被选中的 tile 内部是 glTF / GLB:splat 表示为点图元,属性包括 POSITION、KHR_gaussian_splatting:ROTATION / SCALE / OPACITY 和 SH 系数,并通过可选的 COLOR_0 提供点云 fallback。
值得注意的是,CesiumJS 当前并不是”任意 glTF splat 都能渲染”——代码会检查 tileset 是否同时声明 KHR_gaussian_splatting 和 KHR_gaussian_splatting_compression_spz_2。加载后,它把选中的 tile 展开成独立的运行时数组(positions、rotations、scales、colors、packed SH),再聚合成一个整体渲染 snapshot。这意味着:
Cesium 的流式单位是 tile,运行时组织方式是 CPU 结构化数组 + GPU 纹理打包。
SparkJS:两层渲染器原生存储
Spark 有两层存储。
第一层 PackedSplats:核心布局固定为每 splat 16 字节——float16 的中心点 xyz、3 字节 log 编码的 scale、4 字节 RGBA、octahedral-plus-angle 压缩的四元数。SH 单独存放(sh1 每 splat 2 word,sh2 / sh3 各 4 word)。本质上是 AoS 的 16 字节 core record + SoA 的 SH 旁路 buffer 的混合设计。
第二层 .rad:Spark 2.0 引入,面向 LOD、流式加载和随机访问。官方 changelog 描述它支持自定义字段编码、列式存储、压缩和分块随机访问。运行时有两种访问模式:对单体 .rad 文件做 byte-range fetch,或按 header 解引用外部 .radc chunk 文件。page size 硬编码为 65,536 splat/页,共享 GPU pool 桌面端默认 16,777,216 splat。
SPZ 的角色差异
SPZ(Niantic 开源的高斯压缩格式)对两个生态都重要,但定位不同:对 Cesium,SPZ 是 glTF 扩展流程中的压缩路径;对 Spark,SPZ 只是输入格式之一,.rad 才是大规模 LOD 场景的原生流式格式。简单说:SPZ 是交换 / 传输 codec,.rad 是面向运行时的场景交付 codec。
格式对比一览
| 属性 | Cesium 3D Tiles + glTF | SparkJS 2.0 |
|---|---|---|
| 主容器 | 3D Tiles tileset + glTF/GLB content;层级、metadata、availability 来自 3D Tiles | PackedSplats(内存紧凑表示)+ .rad/.radc(预构建 LOD 流式场景) |
| 数据组织 | glTF 点图元属性 → 运行时数组 → 聚合 snapshot | 16 字节 packed core record + 独立 SH buffer;.rad 列式且可分块 |
| 量化 / 压缩 | glTF 允许 float / normalized integer;Cesium 当前要求 SPZ 扩展 | core 本身即固定宽度量化;SH bit-pack;.rad 再加压缩和分块随机访问 |
| Metadata / 索引 | tile/content metadata、implicit subtree availability、Morton ordering | header metadata + 运行时 chunk↔page 映射、freelist、LRU |
| 流式单位 | tile content 文件、subtree 文件 | 网络层 chunk;GPU 端 page(65,536 splat/页) |
| 标准状态 | 开放标准路径,KHR_gaussian_splatting 为 Release Candidate,拟纳入 3D Tiles 2.0 | 开源但 Spark 特定,目前不是行业标准 |
LOD 策略:tile 级误差 vs splat 树预算
这是两个方案最根本的分歧点。
Cesium:tile 级 screen-space error
Cesium 的 LOD 完全继承自 3D Tiles:每个 tile 有 geometricError 和 REPLACE / ADD 细化模式,运行时根据 geometric error 和相机状态计算 screen-space error,超过阈值就细化。LOD 单位是 tile,误差指标是 tile 级 screen-space error,而不是单个 splat 的重要性。
Spark:Gaussian splat tree + 硬预算
Spark 构建一棵 Gaussian splat tree,每个内部 splat 是其子节点的下采样表示。后台遍历用按 pixel_scale(splat 投影到屏幕上的角尺寸)排序的优先队列,停止条件有三:frontier 中最大的 splat 已小于一个像素、节点没有子节点、或继续细化会超出 splat budget N。它还支持 multi-tree traversal 和 foveation(注视点优化),budget 在多个对象之间按屏幕相关性全局分配。
Cesium 回答”该显示哪些空间 tile?”,Spark 回答”在给定 budget 下,哪个 splat-tree frontier 画面最好?”
这个差异决定了大部分下游行为:Cesium 的粗粒度单位换来互操作性和 metadata 能力,但细化质量依赖 tiler 的空间划分和 geometric error 分配(Cesium ion 的 tiler 并未开源);Spark 直接控制渲染复杂度和细节分布,且遍历成本是 O(N log N)——相对被渲染的 splat 数而非总场景规模——但只在 Spark 自己的生态内有效。
流式加载管线
Cesium:选 tile → 聚合 snapshot → 原子提交
- 3D Tiles traversal 选出可见 tile;
GltfLoader加载 content,GaussianSplat3DTileContent提取并缓存 positions / rotations / scales / SH;GaussianSplatPrimitive把选中 tile 聚合成 pending snapshot;- WASM texture generator 把属性打包进 GPU 纹理;
- WASM radix sorter 生成排序后的 index buffer,snapshot 原子提交;
- 稳态下只有相机移动超过阈值才重新排序。
Spark:操作系统式虚拟内存
PagedSplats先从一个小的前置 byte range 解析.radheader(64 KB → 256 KB → 1 MB 逐步扩大);- 通过 byte-range fetch 或外部
.radc文件名获取单个 chunk,在 worker 中解码; SplatPager维护共享 page pool、freelist、LRU、chunk→page 映射和预分配纹理;- 可见实例只上传一个 index indirection texture,把逻辑输出顺序映射到 page-resident 的 packed splats。
这就是把操作系统风格的虚拟内存应用到 splat:流式单位 = chunk,驻留单位 = page,绘制间接寻址单位 = index texture。
需要注意的是,Spark 的 pager 尚未完全成熟:已有 open issue 报告被 dispose 的 PagedSplats 不会中止进行中的 fetch、孤儿 fetch 会在 pager map 中留下 stale 引用,以及 .rad 特有的动画卡顿。这些不否定架构本身,但选生产路径时需要权衡。
统一的流式生命周期
两条路径抽象后是同一个生命周期:selector 决定需要什么 → 网络获取 tile 或 chunk → worker / WASM 解码 → 上传纹理 / 索引 → 排序并绘制。
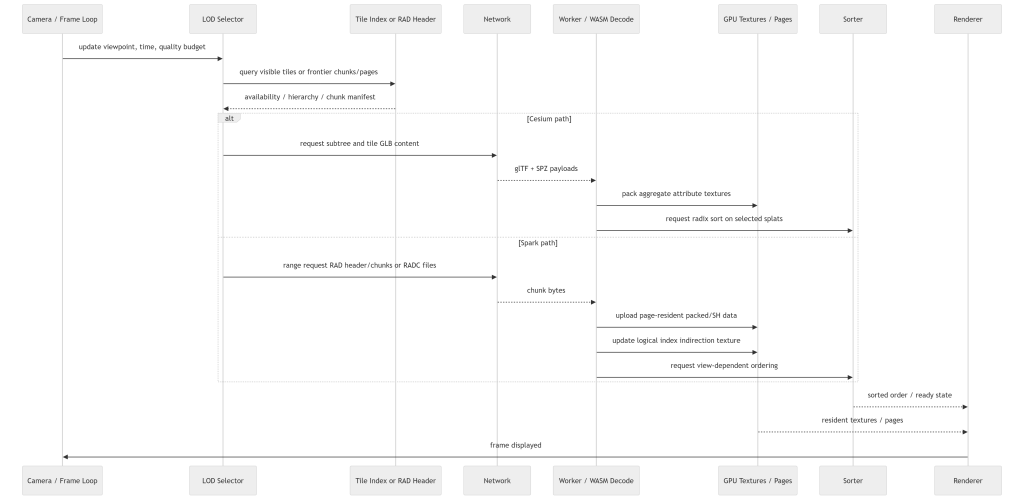
运行时内存与 GPU 布局
两个系统的公开实现都是 WebGL-first、以纹理为中心的,但活跃内存成本差异显著。
Cesium:CPU 端以 Float32Array 存 positions / rotations / scales,Uint8Array 存 colors,SH 以 half-float pair 打包进 Uint32Array。GPU 上每个 splat 在主属性纹理中占两个 RGBA32UI texel(32 字节),SH 在另一张整数纹理中。绘制状态:关 culling、开 depth test、关 depth write、premultiplied-alpha blending。
Spark:RGBA32UI 的 DataArrayTexture 存 16 字节 packed core record,SH 纹理以 RG32UI / RGBA32UI 存储,PagedSplats 再加一张 RGBA32UI 2D indices texture 做逻辑序列间接寻址。排序可选 radial distance 或 z-depth,文档还建议关闭浏览器 MSAA(对 splatting 无益且伤性能)。
存储与活跃内存估算
| 指标 | Cesium | SparkJS 2.0 |
|---|---|---|
| 源文件 B/splat(仅 core) | 估算 24–36 B(SPZ 可显著降低磁盘大小) | 精确 16 B |
| 源文件 B/splat(含 SH3) | 估算约 228 B(全 float32 SH 时) | 精确 56 B(16 core + 8 sh1 + 16 sh2 + 16 sh3) |
| 活跃 GPU B/可见 splat(仅 core) | 约 32 B(两个 RGBA32UI texel) | 约 20 B(16 core + ~4 index) |
| 活跃 GPU B/可见 splat(含 SH3) | 约 152 B | 约 60 B |
| 解码 / staging 模型 | tile decode + transform + 聚合快照 + 纹理打包 + sort | worker chunk decode + page 上传 + index 更新 + sort |
(Spark 核心数值精确,Cesium 字节数为估算——glTF accessor 允许多种 component type,SPZ 压缩会显著改变磁盘大小。)
另一个值得注意的细节是 Cesium 的硬上限行为:当 packed splat 纹理将超过最大纹理尺寸时,代码会截断可见 splat 数量并临时增大 screen-space error;SH 纹理超限时则在该快照中禁用 SH、回退到仅颜色渲染。这说明 Cesium 的可见 splat 渲染器主要受限于当前 tile 集合的纹理容量,而非一个固定的应用级 splat 预算。
性能特征与取舍
带宽:Cesium 通过标准层级结构减少网络复杂度——subtree availability 在 fetch 之前就告诉客户端哪些 tile 存在;但一旦 tile 被选中,请求粒度仍是整个 tile content 文件。Spark 以自定义传输契约为代价,换来只获取填满当前预算 frontier 所需的 chunk,并在多个对象间复用一个固定 GPU pool。
CPU:Cesium 的重负载发生在 tile 集合变化时——聚合、转换、打包、排序,架构单位是”重建可见 snapshot”。Spark 把工作推到持续的后台维护中(优先队列遍历、chunk 解码、page 驻留管理、index 更新),避免每次视角轻微变化都重建单体快照。
GPU:在场景巨大但屏幕预算受限时,Spark 优势最清晰——固定 splat 渲染预算使渲染复杂度几乎不随总场景规模变化(桌面默认约 150 万 LOD splat,移动端 50 万)。Cesium 用 screen-space error 控制 tile 细化,作为通用 3D Tiles 机制很好,但作为 Gaussian 专用的渲染预算调控器不够直接。
移动端:Spark 有更明确的预算叙事——iOS 上 paged splat pool 默认降至约 629 万,其他移动设备 839 万(桌面 1678 万),并直接暴露 foveation 控制。Cesium 的 fallback 健壮但偏机会式(超限截断、禁 SH)。当设备级可预测性比标准对齐更重要时,Spark 更合适。
决策表
| 属性 | Cesium 3D Tiles + glTF | SparkJS 2.0 |
|---|---|---|
| 格式 | 开放标准路径(当前还要求 SPZ 压缩扩展) | 开源但 Spark 特定,.rad 非外部标准 |
| LOD 单位 | 分层 tile | Gaussian tree node |
| 流式单位 | tile content 文件、subtree 文件 | 网络层 chunk、GPU 端 page |
| 字节 / splat | 更高且变化更大(GPU core ~32 B,含 SH3 ~152 B) | 更低且更可控(core 精确 16 B,含 SH3 ~60 B) |
| 解码成本 | tile 切换时的突发成本高 | worker + paging + index 更新,更增量 |
| 最大优势 | 标准、地理空间元数据、互操作、多引擎部署 | 固定预算渲染、细粒度流式、低活跃内存、Three.js 原生集成 |
| 最大弱点 | 请求粒度粗、可见快照重建昂贵 | 传输格式标准化弱、pager / 动画仍有粗糙之处 |
| 最适合 | 地理空间数字孪生、巡检系统、分析叠加、混合 3D Tiles 场景 | Web / XR 产品查看器、交互世界、严格预算的复合场景 |
如何选择
项目必须存在于 Cesium / 3D Tiles / 地理空间技术栈中 → 选 Cesium。决定因素不是原始性能,而是组织杠杆:标准元数据、现有工具链、地理配准、CesiumJS 与 Unreal 生态的部署能力。
项目是自定义 Web renderer,且你控制 viewer、内容管线和网络协议 → 选 Spark。固定 active splat 预算 + 虚拟化 page-resident 内存池,让它在客户端渲染控制和设备级可预测性上明显占优。
未来方向
标准趋势更偏向 Cesium:KHR_gaussian_splatting 已是 Khronos Release Candidate,扩展文本有意为未来的 kernels / projections / sorting modes 留出空间,Cesium 也公开将 splats 定位为 3D Tiles 下一步提案的一部分。一旦 splat 成为 glTF / 3D Tiles 中持久的开放载荷,这些生态的每一次增量改进都会惠及 splat delivery。
Spark 的贡献更偏架构:它证明了 Gaussian-native runtime 可以把 splats 当作虚拟化工作集而非单体点云。即使 .rad 永远不会成为标准,固定预算、页表、multi-tree frontier selection、foveation、分块随机访问这些思想,也很可能影响未来的 splat 流式系统——包括潜在的标准载荷扩展或基于 WebGPU compute 的运行时。
未解决问题:.rad 的公开规范细节仍薄弱;SPZ 伴随扩展的 Khronos 最终命名还在变化中;两边都缺一个公开的、严格 apples-to-apples 的 benchmark suite(同场景、同 SH degree、同排序模式、同设备预算)。所以今天最稳妥的结论是架构层面的,而非 benchmark 驱动的:
Cesium 优化的是标准化地理空间流式加载;Spark 优化的是由渲染器控制的 splat 虚拟化。