
简介
C++ 支持程序中的部分代码通过线程并发执行,在编写此类程序时,必须采取额外的步骤,确保线程之间共享的数据不会导致竞争条件。通常,竞争条件通过适当使用互斥锁和锁来避免。然而,在高性能代码中,互斥锁有时可能过于昂贵,尤其是对于争用激烈的数据。C++ 提供了一些替代方案。
平衡性能的策略
在过去的几十年中, CPU 性能快速提升,内存性能的发展相对滞后。
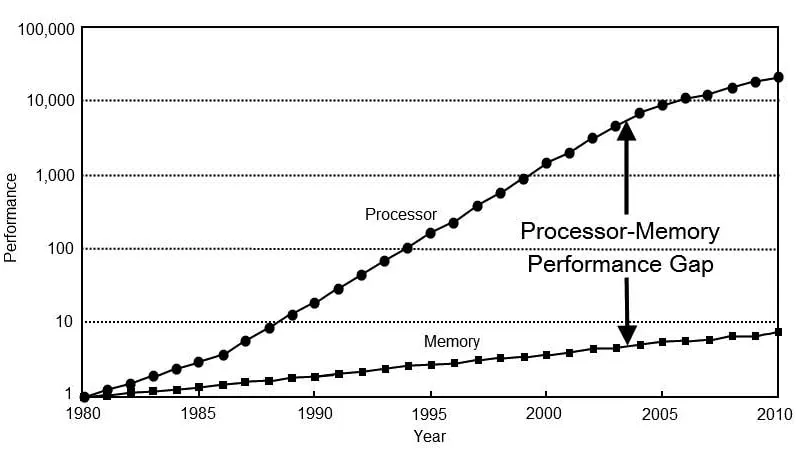
为了避免整体性能受到内存的限制,CPU 设计师不得不采取以下策略:
- CPU缓存(Memory caching)
- 指令级并行(Instruction parallelization)
- 推测执行(Speculative execution)
- 多个 CPU核心
所有这些策略完全由硬件执行。作为程序员的你既无法知道,也无法真正影响底层发生的事情。此外,编译器实现者还会采取自己的策略,包括:
- 常量折叠(Constant folding)
- 复制省略(Copy elision)
- 语句提升(Statement hoisting)
- 指令调度(Instruction scheduling)
- 循环展开(Loop unrolling)
- 以及很多其他的策略……
编译器可以自由地进行任何优化,只要这些优化不改变程序的可观察行为。如果你的程序只有一个线程,你可以不用过多的关心硬件或编译器所采取的策略。然而,一旦你使用了多个线程,就必须高度关注底层发生的事情。
原子操作
在进行多线程编程时,你会听到“原子操作”这个术语。那么,“原子操作”到底是什么意思呢?它有三个相关但不同的含义:
- 一个值的操作(读或写)在没有其他线程介入的情况下完成,例如,在任何 CPU 上写入单字节值,或在 32 位 CPU 上写入 16 位或 32 位值,或者在 64 位 CPU 上写入 64 位值。
- 更新后的值对其他 CPU 可见。
- 多个值的操作在没有其他线程介入的情况下完成,例如,一起更新 A 和 B (“事务性”)。
“原子操作”通常指的是第一个含义;它通常也指第二个含义;或者是这三者的结合。这三个含义在下文中会被反复提及。
一个不太好的示例
考虑以下代码,其中主线程创建了另一个线程。只要 shutdown 为 false,两个线程就会继续运行。为了关闭,主线程将 shutdown 设置为 true。作为响应,两个 while 循环将退出,主线程将等待其他线程结束。不幸的是,这段代码是错误的。
bool shutdown;
void thread_1() {
while ( !shutdown ) {
// ...
}
}
int main() {
std::thread t1{ thread_1 };
while ( !shutdown ) {
// ...
if ( some_condition )
shutdown = true;
}
t1.join();
}
它是错误的,因为 shutdown 被多个线程不当共享。有人错误地认为:“它只是一个布尔值,一个字节,因此它当然是线程安全的,因为你不可能读取或写入半个字节,所以它一定是原子的。”
问题在于,虽然这个说法在某种程度上是对的,但它并不充分。布尔值仅在第一个含义下是原子的;它在第二个含义下并不是原子的。也就是说,仅仅因为一个线程更新了布尔值,并不意味着其他线程(在其他 CPU 上运行的线程)能看到这个更新后的值。
不好的修复方式:volatile
如果把代码改成这样,那么是线程安全的吗?
volatile bool shutdown;
在 C++ 中,试图使用 volatile 来确保线程安全总是错误的。
volatile 的主要目的是告诉编译器不要优化对某个变量的读取或写入操作。这意味着每次访问 volatile 变量时,编译器都必须从内存中重新读取该变量,而不是使用可能已经缓存的值。它通常用于硬件寄存器、信号处理、内存映射 I/O 或与 setjmp() 配合使用等场景。
即使某个变量是 volatile,它也不意味着一个线程对这个变量的修改能够立即对其他线程可见。volatile 并没有像 std::atomic 或内存屏障那样提供内存同步机制。因此,即使一个线程修改了 volatile 变量,另一个线程可能仍然无法立刻看到这个修改。
稍微好点的修复方式:Mutexes & Locks
一个经典且正确的修复方式,是使用 mutex:
bool shutdown;
std::mutex shutdown_mux;
void thread_1() {
while ( true ) {
// ...
std::lock_guard<std::mutex> lock{ shutdown_mux };
if ( shutdown )
break;
}
}
int main() {
std::thread t1{ thread_1 };
while ( true ) {
// ...
if ( some_condition ) {
std::lock_guard<std::mutex> lock{ shutdown_mux };
shutdown = true;
break;
}
}
t1.join();
}
互斥锁使得 shutdown 在第一个和第二个含义上都变得原子性。虽然对于这个程序来说并非必需,互斥锁也使得操作在第三个含义上变得原子性,因此它们是确保程序线程安全的最通用、一劳永逸的工具。然而,C++ 提供了其他工具,这些工具能够提供更为定制化的解决方案,特别在高性能代码中非常有用。
注意事项
即使使用普通的互斥锁,编写安全的多线程代码也很难做到正确。在考虑这些技术之前,要注意:
- 使用高效算法比锁技术更为重要。例如,一个使用较慢互斥锁的 N⋅log(N) 算法,很可能比一个使用更快锁(或无锁)技术的 N2 算法更具性能优势。
- 评测代码是否在锁操作上花费了过多的时间。
- 只有当锁操作占用了显著的时间百分比时,才考虑以下的技术。
更好的修复方式:std::atomic
虽然使用互斥锁是正确的,但它们的开销相对较大。在使用布尔值的情况下,一个更轻量的解决方案是:
std::atomic<bool> shutdown;
使用 std::atomic<T> 使 shutdown 在第二个含义上变得原子性。std::atomic<T> 类专门为所有内建类型(如 bool、char、int 等)以及所有指针类型(如 T*)提供支持。它甚至可以用于你自己定义的类型 T,但仅在以下条件下:
T是简单可复制的(即,如果memcpy()可以正确地复制T)。sizeof(T)≤ 16(通常情况下)。
当 T 是整数类型或指针类型时,std::atomic<T> 为其重载了常规操作符:
std::atomic<int> x{ 0 };
x = 1; // x.store(1)
int i = x; // x.load()
++x; // x.fetch_add(1)
x++; // x.fetch_add(1)
--x; // x.fetch_sub(1)
x--; // x.fetch_sub(1)
x += 1; // x.fetch_add(1)
x -= 1; // x.fetch_sub(1)
x &= 1; // x.fetch_and(1)
x |= 1; // x.fetch_or(1)
x ^= 1; // x.fetch_xor(1)
这些操作符是对注释中所示成员函数的简写。虽然操作符很方便,但也可以直接使用成员函数,以便在代码中清晰地表明正在操作的变量是一个 std::atomic 类型。另外:
x = x + 1; // 不等同于 ++x 或者 x += 1
根据第三个含义:这个操作不是线程安全的,因为对 x 的读取和对 x 的写入不符合第三个含义。
无锁的原子操作
尽管 std::atomic<T> 提供的性能优于互斥锁,但并不能保证总是如此。在特定条件下,对于特定 CPU 上的类型 T,可以使用 is_lock_free() 和 is_always_lock_free() 来检查是否为无锁。那些条件包括:
- 访问未对齐的值,例如,在一个内存地址上读取
int,该地址不能被sizeof(int)整除(假设 CPU 即使能够处理,也不会生成总线错误)。 - 运行时 CPU 调度,例如,在初始化过程中,某个程序可能会检测 CPU 是否支持
cmpxchg16b指令,如果不支持,可能会被迫使用锁。
唯一能保证在所有 CPU 和所有条件下始终无锁的类型是 std::atomic_flag,它是 std::atomic<bool> 的特例。(稍后将展示使用 std::atomic_flag 的例子。)
内存屏障
仅仅原子性(无论是哪个含义)不足以确保线程安全,因为内存操作的顺序不一定与程序中语句的顺序匹配。为什么?因为硬件、编译器,或两者可能会重新排序操作以提高性能。
内存屏障通过选择性地禁止跨越屏障的内存操作重排序,帮助确保线程安全。关于内存屏障有时令人困惑的是,它们控制的是操作的顺序,而不是操作本身。
memory_order_seq_cst:顺序一致性
这是最安全的内存顺序,因此它是默认设置。例如,std::atomic<T>::fetch_add() 的函数签名是:
T fetch_add( T arg, std::memory_order order
= std::memory_order_seq_cst ) noexcept;
它也是效率最低的,因为它在所有线程之间建立了一个全局的内存排序(瓶颈)。在特定情况下,可以使用更高效的内存顺序。
memory_order_relaxed: 无序
这是最不安全的内存顺序,因为它不保证操作顺序或同步,但仍然保证修改顺序。那这有什么好处呢?一个典型的使用场景是递增引用计数:
template<typename T>
class shared_ptr {
public:
// ...
private:
struct counted_obj {
// ...
std::atomic<size_t> _count;
T _obj;
};
counted_obj *const _co;
void _inc_ref() noexcept {
_co->_count.fetch_add( 1, std::memory_order_relaxed );
}
// ...
};
在这一点上,你可能会问类似这样的问题:“如果没有同步,这怎么可能正常工作?线程 1 不会把值从 N 增加到 N+1,而线程 2 也可能把旧值 N 增加到 N+1 吗?”
并不会。有两个原因:
- 每次递增仍然是原子的(根据第一个和第二个含义),因此每个线程总是能看到最新的值。
memory_order_relaxed的作用是允许硬件或编译器重新排序与_count无关的其他操作,无论是在递增之前还是之后,以提高整体性能,而不是专门提高_count的性能。 - 由于
_count是私有数据结构的一部分,保证不会有其他线程根据其当前值采取任何有条件的操作。换句话说,当只执行递增操作,并且不改变任何线程的控制流时,使用memory_order_relaxed是安全的。
当递减引用计数时,memory_order_relaxed 是不安全的。当你递减引用计数时,通常会在计数为 0 时销毁对象或释放资源。在这种情况下,确保操作的顺序非常重要。如果你使用 memory_order_relaxed,就无法保证 fetch_sub 操作的顺序性,这可能导致以下问题:
- 竞态条件:一个线程可能会在另一个线程递减引用计数后销毁对象之前访问它,导致访问已经被销毁的对象,造成未定义行为。
- 不保证同步:虽然递减操作本身是原子的,但是其他线程的操作可能会看到过时的引用计数值,从而导致错误的逻辑或资源泄露。
实际情况是,尽量不要使用它,除非你能够证明它的使用是正确的,并且确实显著提高了性能。正确使用 memory_order_relaxed 是非常困难的。
memory_order_acquire 和 memory_order_release
这两个内存顺序更安全,并且总是成对使用:
memory_order_release(与store()一起使用)用于“发布”信息:发布后,不能对任何访问进行重排序。memory_order_acquire(与load()一起使用)用于“订阅”信息:订阅前,不能对任何访问进行重排序。
在这个例子中,shared_data 在两个线程之间共享,data_ready 充当信号量:
int shared_data;
std::atomic<int> data_ready{ 0 };
void producer() {
shared_data = 42;
data_ready.store( 1, std::memory_order_release );
}
void consumer() {
while ( data_ready.load( std::memory_order_acquire ) == 0 )
;
assert( shared_data == 42 ); // always true
}
int main() {
std::thread t1{ producer };
std::thread t2{ consumer };
t1.join();
t2.join();
}
生产者设置 shared_data 然后发出数据已准备好的信号(或“发布”它)。对 shared_data 的写操作在对 data_ready 的写操作之前“发生”,因为使用 memory_order_release 保证了对 shared_data 的写操作不能在 data_ready 之后被重排序。
与此同时,消费者忙等待 data_ready 上的信号,然后安全地读取 shared_data。对 data_ready 的读操作在对 shared_data 的读操作之前“发生”,因为使用 memory_order_acquire 保证了对 shared_data 的读操作不能在 data_ready 之前被重排序。
需要注意的事项:
shared_data本身不需要是原子的。这对于无法使数据原子化的数据尤其有用,比如数据太大或不是简单可复制的。- 你可以设置任意数量的数据,然后“同时发布”所有数据。
此时,你可能会问忙碌等待是否高效。一般来说,当等待时间很短时,它是高效的——比锁定和解锁互斥锁所需的时间要短。可以使用 std::atomic_flag 来实现一种通用的自旋锁:
std::atomic_flag mutex = ATOMIC_FLAG_INIT;
class spin_lock {
public:
explicit spin_lock( std::atomic_flag *mutex ) noexcept :
_mutex{ mutex }
{
while ( !_mutex->test_and_set( std::memory_order_acquire ) )
;
}
~spin_lock() noexcept {
_mutex->clear( std::memory_order_release );
}
private:
std::atomic_flag *const _mutex;
};
memory_order_consume
这种内存顺序是 memory_order_acquire 的一种特例,它允许操作按照依赖顺序进行,这在弱序列 CPU(如 ARM、PowerPC,但不是 x86)上可以更高效。从之前的例子来看:
int shared_data;
std::atomic<int> data_ready{ 0 };
shared_data 和 data_ready 之间实际上没有任何依赖关系,除了我们在脑海中的理解 —— 编译器无法知道这一点。为了创建一个编译器可以利用的实际依赖关系,从而保持操作的依赖顺序,我们可以改为这样做:
std::atomic<int*> data_ready{ nullptr };
void producer() {
static int shared_data;
shared_data = 42;
data_ready.store( &shared_data, std::memory_order_release );
}
void consumer() {
while ( (data_ready.load( std::memory_order_consume )) == nullptr )
;
assert( *data_ready == 42 ); // always true
}
现在,我们通过使用指针和指向的值创建了一个实际的依赖关系,即在解引用指针之前必须先加载指针的值。编译器可以在不使用额外且更昂贵的内存屏障的情况下保持这个顺序。
memory_order_acq_rel
这种内存顺序是将 memory_order_acquire 和 memory_order_release 结合成一个,用于读-修改-写操作:在操作前后,不能对任何访问进行重排序。一个典型的使用场景是递减引用计数:
template<typename T>
class shared_ptr {
public:
// ...
~shared_ptr() noexcept {
if ( _co->_count.fetch_sub( 1, std::memory_order_acq_rel ) == 1 )
delete _co;
}
// ...
};
不能在这里使用 memory_order_relaxed 的原因是,另一个线程中对引用计数对象的使用可能被重新排序到删除操作之后,从而导致未定义行为。
std::atomic_thread_fence()
使用 std::atomic 配合 memory_order_relaxed 是无屏障的原子操作;而使用 std::atomic_thread_fence() 则是没有特定原子的屏障操作。如果你想要同时更新多个原子值,它会很有用。例如,当你打算这样做时:
atomic<int> x, y; x.store( 1, std::memory_order_release ); y.store( 2, std::memory_order_release );
实际上可以这样做:
x.store( 1, std::memory_order_relaxed ); y.store( 2, std::memory_order_relaxed ); std::atomic_thread_fence( std::memory_order_release );
但是,在以下情况时,情况会有点不一样:
std::atomic<int> sync{ 0 };
// (1) load & store operations
sync.store( 1, std::memory_order_release );
// (2) store operations
在(1)中的操作不会在将 sync 存储到(2)时进行重排序;然而,(2)中的存储操作可以在释放操作前被重排序到(1)之前。
std::atomic_thread_fence() 施加了比相同内存顺序下对原子操作的操作更强的排序保证。给定以下情况:
// (1) load & store operations std::atomic_thread_fence( std::memory_order_release ); // (2) load operations sync.store( 1, std::memory_order_relaxed ); // (3) store operations
在(1)中的操作不会在所有后续的存储操作到(3)后进行重排序,而(3)中的存储操作不能在屏障前重排序到(1)之前。然而,由于 memory_order_release 仅控制存储操作,(2)中的加载操作可以在释放操作前重排序到(1)之前。
memory_order_acquire 的规则类似,只不过它仅控制加载操作,并且强制执行相反方向的排序。它们的差异很微妙。通常情况下,关联到特定原子的 acquire 或 release 操作是更为推荐的做法。
Compare-and-Swap (CAS)
比较并交换(CAS),顾名思义,是比较和交换操作同时进行的原子操作(符合所有原子含义)。从概念上来说,它的实现是:
template<typename T>
bool atomic<T>::compare_exchange( T &expected, T desired ) {
if ( this->_value == expected ) {
this->_value = desired;
return true;
}
expected = this->_value;
return false;
}
除非以原子方式执行。其基本思路是检查原子变量的值,并:
- 如果它是你期望(或希望)的值,那么(且仅在此情况下)将其设置为一个新的期望值;或者:
- 如果它不是你期望(或希望)的值,意味着其他线程已经改变了该值,那么什么也不做。你可以自由地重新尝试设置这个值。
实际上,有两种变体:compare_exchange_weak() 和 compare_exchange_strong()。
例如,我们可以使用 CAS 重新实现之前的 spin_lock 类:
std::atomic<bool> mutex;
class spin_lock {
public:
explicit spin_lock( std::atomic<bool> *mutex ) noexcept :
_mutex{ mutex }
{
bool flag = false;
while ( !_mutex->compare_exchange_weak( flag, true ) )
flag = false; // must reset
}
~spin_lock() noexcept {
_mutex->store( false );
}
private:
std::atomic<bool> *const _mutex;
};
使用 CAS,来看看 _mutex 的值:
- 如果是
false,则意味着它当前是解锁的,因此将其设置为true表示现在已加锁并返回true。 - 如果是
true,则意味着它当前已被锁定(由另一个线程),因此不设置值并返回false。
请注意,在这种情况下,flag 的第一个参数是一个输入/输出参数,即使我们不关心它,它也会被设置为原子的当前值(这里是 true)。这迫使我们在进行下一次尝试之前,将 flag 重置为 false。
无锁操作
CAS 的一个主要使用场景是它允许你在数据结构上实现无锁操作。例如,一个无锁栈实现的一部分可能是:
template<typename T>
class stack {
public:
struct node {
node *_next;
T _data;
explicit node( T &&data ) : _data{ std::move( data ) } { }
};
void push( T &&data ) {
node<T> *new_node = new node<T>{ std::move( data ) };
new_node->_next = _head.load( std::memory_order_relaxed );
while ( !_head.compare_exchange_weak(
new_node->_next, new_node,
std::memory_order_release,
std::memory_order_relaxed ) );
}
private:
std::atomic<node<T>*> _head;
};
在创建一个新节点后,我们尝试更新 _head:
- 如果它仍然等于
new_node->_next(即_head的原始值),则使用第三个参数指定的内存顺序,将_head更新为指向new_node。 - 如果它不相等,意味着另一个线程已经偷偷更新了
_head,使其指向不同的新节点,因此不做任何操作并重新尝试。(请注意,new_node->_next已经更新为新的_head,它指向了不同的节点,使用的是第四个参数指定的内存顺序。)
compare_exchange_weak() vs compare_exchange_strong()
compare_exchange_weak() 的存在意味着有 compare_exchange_strong() —— 它确实存在。它们之间的区别是:
compare_exchange_strong()只有在当前值与预期值不相等时才会失败(返回false)。compare_exchange_weak()也可能会失败,也就是“虚假失败”。
“虚假失败”是弱序列 CPU(例如 ARM 和 PowerPC,但不是 x86)上的一种特性,在这种情况下,操作因其他原因失败,而不是因为值不等于预期值。
那么,如果 compare_exchange_strong() 从不发生虚假失败,为什么还会有 compare_exchange_weak() 的存在呢?在回答这个问题之前,让我们看看它们的概念性实现:
enum class cas_result {
EQUAL,
NOT_EQUAL,
SPURIOUS_FAILURE
};
template<typename T>
cas_result cas_weak_impl( atomic<T> *p, T &expected, T desired );
template<typename T>
bool atomic<T>::compare_exchange_weak( T &expected, T desired ) {
return cas_weak_impl( this, expected, desired ) == cas_result::EQUAL;
}
template<typename T>
bool atomic<T>::compare_exchange_strong( T &expected, T desired ) {
cas_result cr;
do {
cr = cas_weak_impl( this, expected, desired );
} while ( cr == cas_result::SPURIOUS_FAILURE );
return cr == cas_result::EQUAL;
}
假设只有 cas_weak_impl() 实现了 CAS 的弱版本:
compare_exchange_weak()是一个简单的包装器,封装了cas_weak_impl()。- 而
compare_exchange_strong()则在其外面加上了一个循环,有效地过滤掉了虚假失败。这里需要记住的关键是:它包含一个循环。
因此,compare_exchange_weak() 的优点是:
- 虚假失败通常不会发生得太频繁。
- 当你的代码本来就使用循环时,弱版本在弱序列 CPU(如 ARM、PowerPC,但不是 x86 —— 但它并不更差)上会提供更好的性能。
- 可以检测到 ABA 问题(在弱序列 CPU 上)。
那么,为什么 compare_exchange_strong() 会存在呢?
- 如果你有一个循环只是为了过滤虚假失败,那就不要这样做:使用
compare_exchange_strong()。 - 但是,如果你本来就有一个循环,那么使用
compare_exchange_weak()。 - 不过,如果处理虚假失败的代价较高(例如,你必须丢弃并重建一个新对象),那就使用
compare_exchange_strong()。 - 但是,
compare_exchange_strong()不会检测 ABA 问题。
鉴于这一切,你可能会想,什么时候 compare_exchange_strong() 不需要循环?一个例子是实现 try_lock():
bool my_try_lock( std::atomic<bool> *mutex ) noexcept {
bool flag = false;
return mutex->compare_exchange_strong( flag, true );
}
ABA 问题
ABA 问题可以通过以下方式说明。假设线程 1 执行以下步骤:
- 读取一个内存位置(值为 “A”)。
- 执行一些语句。
- 再次读取相同的内存位置(值仍然是 “A”)。
- 比较原始值和最近读取的值(它们相等)。
- 结论:值没有变化。
问题在于,假设线程 2 在线程 1 执行步骤 2 的时候执行了以下步骤:
- 将 “B” 写入相同的内存位置。
- 执行一些语句。
- 将 “A” 写入相同的内存位置。
当线程 1 执行步骤 3 时,它读取到 “A” 并认为没有任何变化 —— 即使实际上发生了变化。你现在可能会问:“如果值 ‘A’ 没有变化,为什么这会有影响?”
答案是:有时它不重要 —— 但有时它确实很重要。
考虑之前提到的 stack<T>::push() 代码(为了方便这里重复一遍):
void push( T &&data ) {
node<T> *new_node = new node<T>{ std::move( data ) };
new_node->_next = _head.load( std::memory_order_relaxed );
while ( !_head.compare_exchange_weak(
new_node->_next, new_node,
std::memory_order_release,
std::memory_order_relaxed ) );
}
以及以下的示意图:
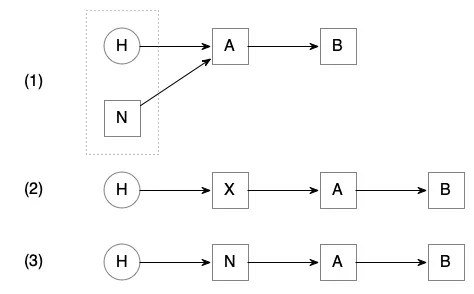
状态 (1) 显示了初始条件,其中 A 和 B 是栈上的节点,_head(H)指向 A,new_node(N)也将其 _next 指向 A。虚线框包含了正在比较的 _head 和 new_node->_next。状态 (3) 显示了期望的最终状态,_head 指向 new_node,而 new_node->_next 指向 A。
但是,如果另一个线程在进入 while 循环之前悄悄地插入了一个新节点 X(如状态 (2) 所示),然后立即将其弹出呢?此时,_head 和 new_node->_next 仍然都指向 A,因此 _head 将被设置为 new_node —— 这是正确的。在这种情况下,ABA 问题实际上不是一个问题。
但是现在考虑一下 stack<T>::pop() 的代码可能是什么样的:
T pop() {
node<T> *first = _head.load( std::memory_order_relaxed );
while ( first != nullptr &&
!_head.compare_exchange_weak(
first, first->_next,
std::memory_order_release,
std::memory_order_relaxed ) );
if ( first == nullptr )
throw empty_stack_exception{};
T ret_val{ std::move( first->_data ) };
delete first;
return ret_val;
}
以及以下的示意图:
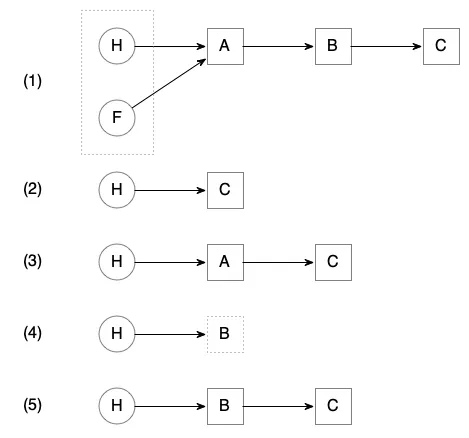
状态 (1) 显示了初始条件,其中 A、B 和 C 是栈上的节点,_head(H)和 first(F)都指向 A。虚线框包含了正在比较的 _head 和 first。状态 (5) 显示了期望的最终状态,_head 指向 B。
但是,如果另一个线程在进入 while 循环之前悄悄地插入了以下操作,弹出了状态 (2) 中的 A 和 B,然后推入了状态 (3) 中的 A 呢?此时,_head 和 first 仍然指向 A,因此 _head 将被设置为 first->_next —— 这是错误的!为什么呢?
最初,first 指向 A,而 A 的 _next 指向 B,因此 first->_next(即比较中的期望值)应该是 B。但 B 在 (2) 中被删除了,所以我们会最终进入状态 (4),其中 _head 是指向已删除的 B 的悬空指针。在这种情况下,ABA 问题确实是一个问题!(在 push() 中这不是问题,因为 new_node 的期望值不可能变陈旧。)
更糟糕的是,这个问题没有简单的解决办法。在这种情况下,问题在于期望值表达式的一部分可以发生变化。虽然 first 保持不变,但 first->_next 指向的内容可以发生变化。即使是专家,检测 ABA 问题也很难。
如何解决这个问题?
- 使用互斥锁(mutex)和锁。
- 实现版本化指针。
- 实现危险指针(hazard pointers)。
Versioned Pointers
版本化指针是一个普通指针,加上一个额外的“版本号”,每次指针的值发生变化时,版本号都会递增。从概念上讲,它类似于以下内容:
template<typename T>
class vers_ptr {
public:
vers_ptr() noexcept : _ptr{ nullptr }, _vers{ 0 } { }
vers_ptr( T *ptr ) noexcept : _ptr{ ptr }, _vers{ 1 } { }
vers_ptr& operator=( T *ptr ) noexcept {
set( ptr );
return *this;
}
// ...
private:
T *_ptr;
uintptr_t _vers; // must be sizeof(T*) for cmpxchg16b
void set( T *ptr ) noexcept {
_ptr = ptr;
++_vers;
}
};
static_assert( sizeof( vers_ptr<void> ) == 16 );
然后使用 vers_ptr<node> 代替 node<T*>:
struct node {
vers_ptr<node> _next;
// ...
};
T pop() {
vers_ptr<node> first = _head.load( std::memory_order_relaxed );
while ( first != nullptr &&
!_head.compare_exchange_weak(
first, first->_next,
std::memory_order_release,
std::memory_order_relaxed ) ) ;
// ...
}
// ...
std::atomic<vers_ptr<node>> _head;
这会起作用,因为即使 first 的 _ptr 部分仍然指向 A,它的 _vers 部分会不同,因此 _head 和 first 不会相等,从而 _head 不会被设置为 B,即 first->_next 的过时值。
然而,需要注意的是:
- 只有当 CPU 支持双指针宽度(在 64 位 CPU 上为 16 字节)CAS 时,这才有效(例如,x86_64 就通过
cmpxchg16b指令支持这一功能)。 - 如前所述,
std::atomic<T>的特化要求 T 是“平凡可复制”的 —— 这也是为什么不能实现operator=(vers_ptr<T> const&)的原因。
缓存行
对于许多 CPU,L1 缓存是以“块”的形式组织的,每个缓存行的大小通常在 16KB 到 64KB 之间。为了将给定的内存位置从主内存读入缓存,整个位置及其周围的块大小的字节都会一起读取。同样,为了将给定的内存位置从缓存写回主内存,整个缓存行都会被写入。对于具有引用局部性的代码,块化会带来性能提升。然而,在某些情况下,它也可能导致性能下降。
考虑一个无锁队列的例子:
template<typename T>
class queue {
// ...
std::atomic<node*> _head;
std::atomic<node*> _tail;
};
假设你的代码有一个线程不断地将项推入队列尾部(反复更新 _tail),而第二个线程则从队列头部弹出项(反复更新 _head)。
在给定的代码中,_head 和 _tail 很可能会位于同一缓存行。这意味着更新其中一个会使整个缓存行失效,从而给另一个变量带来不必要的竞争。
在这种情况下,你希望 _head 和 _tail 位于不同的缓存行中,这样更新一个就不会影响另一个。你可以通过使用 alignas 和 hardware_destructive_interference_size 来实现这一点:
template<typename T>
class queue {
// ...
alignas(std::hardware_destructive_interference_size) std::atomic<node*> _head;
alignas(std::hardware_destructive_interference_size) std::atomic<node*> _tail;
};
这会稍微浪费一些内存,但可以确保 _head 和 _tail 位于不同的缓存行。
总结
- 你的算法比锁技术更为重要。
- 一般而言,线程安全和直接使用原子操作与屏障难以做到完全正确。
- 在使用高级线程安全技术之前,先衡量一下代码是否在锁操作上花费了过多时间。
- 只有当锁操作占用了显著的时间百分比时,才考虑使用原子操作和屏障。
- 原子操作和屏障是同一枚硬币的两面。
- 比较并交换(CAS)是一个基本的构建块。
- 注意 ABA 问题。
- 注意缓存行问题。
hi