
关于原子操作,网络上已经有很多文章讨论,通常聚焦于原子的读-修改-写(RMW)操作。然而,这并不是唯一的原子操作类型。还有原子的加载和存储操作,它们同样重要。原子读-修改-写操作(或称“RMW”操作)比原子加载和存储更为复杂。它们允许你从共享内存中的一个变量读取值,同时在其位置写入一个不同的值。
在本文中,我将尝试解释原子加载、存储和 RMW 操作之间的区别,来说明如何安全地在多线程环境中对共享数据进行操作。并比较原子加载和存储与其对应的非原子操作在处理器级别和 C/C++ 语言级别的差异。同时将澄清 C++11 中的“数据竞争”概念。
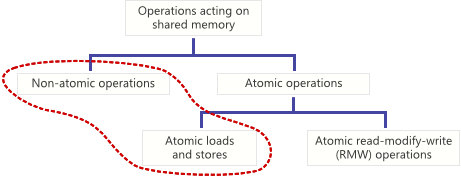
原子读-修改-写(RMW)操作
在 C++11 原子库中,以下所有函数都执行 RMW 操作:
std::atomic<>::fetch_add() std::atomic<>::fetch_sub() std::atomic<>::fetch_and() std::atomic<>::fetch_or() std::atomic<>::fetch_xor() std::atomic<>::exchange() std::atomic<>::compare_exchange_strong() std::atomic<>::compare_exchange_weak()
例如,fetch_add 会从一个共享变量读取值,将另一个值加到它上面,然后将结果写回——这一过程是原子性的、不可分割的。你也可以使用互斥锁来实现相同的功能,但基于互斥锁的版本并不是无锁的。相比之下,RMW 操作设计为无锁的,它们会在可能的情况下利用无锁的 CPU 指令,例如 ARMv7 上的 ldrex/strex 指令。
为什么 C++11 只提供这么少的 RMW 操作?为什么有 atomic fetch_add,却没有 atomic fetch_multiply、fetch_divide 或 fetch_shift_left?这有两个原因:
- 为在实际应用中,几乎不需要这些 RMW 操作。不要误解 RMW 的使用方式。你不能通过将单线程算法的每一步都转化为一个 RMW 操作来编写安全的多线程代码。
- 如果你确实需要这些操作,你可以很容易自己实现它们。正如标题所说,你可以做任何类型的 RMW 操作!
所有 RMW 操作的基础:比较并交换(Compare-and-Swap)
在 C++11 中所有可用的 RMW 操作中,唯一一个绝对必要的操作是 compare_exchange_weak。其他所有的 RMW 操作都可以通过这个操作来实现。它至少需要两个参数:
shared.compare_exchange_weak(T& expected, T desired, ...);
该函数尝试将期望的值存储到共享变量 shared 中,但前提是 shared 的当前值与 expected 匹配。如果成功,它返回 true。如果失败,它会将 shared 的当前值加载回 expected 中,尽管它的名字是 expected,但它是一个输入/输出参数。这就是所谓的比较并交换操作,所有这些都在一个原子、不可分割的步骤中完成。

假设你真的需要一个原子 fetch_multiply 操作,尽管我无法想象为什么需要它。以下是一种实现方法:
uint32_t fetch_multiply(std::atomic<uint32_t>& shared, uint32_t multiplier)
{
uint32_t oldValue = shared.load();
while (!shared.compare_exchange_weak(oldValue, oldValue * multiplier))
{
}
return oldValue;
}
这被称为比较并交换循环(CAS 循环)。该函数会重复尝试将 oldValue 与 oldValue * multiplier 交换,直到成功。如果没有其他线程进行并发修改,compare_exchange_weak 通常会在第一次尝试时成功。另一方面,如果 shared 被另一个线程并发修改,它的值可能会在调用 load 和调用 compare_exchange_weak 之间发生变化,从而导致比较并交换操作失败。在这种情况下,oldValue 将更新为 shared 的最新值,然后循环会重新尝试。
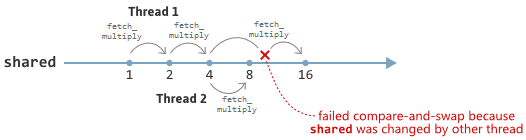
上述的 fetch_multiply 实现是原子性的且无锁的。尽管 CAS 循环可能需要不确定次数的尝试,它仍然是原子性的,因为当循环最终修改 shared 时,它是原子地进行的。它是无锁的,因为如果 CAS 循环的单次迭代失败,通常是因为其他线程成功地修改了 shared。最后这一点依赖于假设 compare_exchange_weak 确实编译为无锁的机器代码。
一般来说,C++11 标准并不保证原子操作是无锁的。因为要支持的 CPU 架构种类太多,并且 std::atomic<> 模板有太多特化的方式。你需要检查你的编译器以确保这一点。在实践中,当以下所有条件成立时,可以比较安全地假设原子操作是无锁的:
- 编译器是最新版本的 MSVC、GCC 或 Clang。
- 目标处理器是 x86、x64 或 ARMv7(以及可能的其他处理器)。
- 原子类型是
std::atomic<uint32_t>、std::atomic<uint64_t>或std::atomic<T*>。
确保共享内存中线程间的一致性
在共享内存上执行的操作如果相对于其他线程在单个步骤内完成,那它是原子操作。当对共享变量执行原子性的存储时,其他线程无法观察到修改的半完成状态。当对共享变量执行原子加载时,它读取的是该变量在某一时刻的完整值。非原子加载和存储则无法提供这些保证。
没有这些保证,无锁编程将变得不可能,因为你无法让不同的线程同时操作共享变量。我们可以将其总结为一个规则:每当两个线程同时操作一个共享变量,并且其中一个操作执行写操作时,两个线程必须都使用原子操作。
如果违反这个规则,并且其中一个线程使用了非原子操作,那么就会发生 C++11 标准所称的数据竞争。C++11 标准并没有告诉你数据竞争为什么不好,只是说明如果发生数据竞争,结果将是“未定义行为”。数据竞争之所以不好,其实原因很简单:它会导致读取和写入的“撕裂”。
一个内存操作可能是非原子的,因为它使用了多个CPU指令,或者即使使用单个CPU指令也不是原子的,或者因为你在编写可移植的代码时无法做出这种假设。我们来看几个例子。
由于多个CPU指令导致的非原子操作
假设你有一个64位的全局变量,初始值为零。
uint64_t sharedValue = 0;
在某个时刻,你将一个64位的值赋给这个变量。
void storeValue()
{
sharedValue = 0x100000002;
}
当你使用GCC为32位x86架构编译这个函数时,它会生成以下机器代码。
$ gcc -O2 -S -masm=intel test.c
$ cat test.s
...
mov DWORD PTR sharedValue, 2
mov DWORD PTR sharedValue+4, 1
ret
...
如你所见,编译器使用了两条独立的机器指令来实现64位赋值。第一条指令将低32位设置为0x00000002,第二条指令将高32位设置为0x00000001。显然,这个赋值操作不是原子的。如果 sharedValue 被多个线程同时访问,可能会发生以下几种问题:
- 如果在两个机器指令之间,一个线程调用
storeValue被抢占,它会将值 0x0000000000000002 留在内存中——这是一个不完整的写入。此时,如果另一个线程读取sharedValue,它将得到一个完全无效的值,这是没有人打算存储的。 - 更糟糕的是,如果一个线程在两个指令之间被抢占,而另一个线程在第一个线程恢复之前修改了
sharedValue,就会导致永久性的不完整写入:一个线程写入了高32位,另一个线程写入了低32位。 - 在多核设备上,即使没有抢占某个线程,也可能发生不完整写入。当一个线程调用
storeValue时,任何在不同核心上执行的线程都可能在只有部分修改可见的时刻读取sharedValue。
并发读取 sharedValue 会带来一系列问题:
uint64_t loadValue()
{
return sharedValue;
}
$ gcc -O2 -S -masm=intel test.c
$ cat test.s
...
mov eax, DWORD PTR sharedValue
mov edx, DWORD PTR sharedValue+4
ret
...
在这里,编译器也使用了两条机器指令来实现加载操作:第一条指令将低32位读取到 eax 中,第二条指令将高32位读取到 edx 中。在这种情况下,如果一个并发的存储操作在两条指令之间变得可见,就会导致一个撕裂读取——即使并发的存储操作是原子的。
这些问题不仅仅是理论上的。Mintomic 的测试套件中包含一个名为 test_load_store_64_fail 的测试用例,其中一个线程使用普通赋值运算符将一堆64位值存储到一个变量中,而另一个线程反复从同一个变量执行普通加载操作,并验证每个结果。在多核 x86 系统上,这个测试如预期一样会持续失败。
非原子性的CPU指令
即使由单条 CPU 指令执行,内存操作也可能是非原子的。例如,ARMv7 指令集包括 strd 指令,它将两个 32 位源寄存器的内容存储到内存中的一个 64 位值。
strd r0, r1, [r2]
在一些ARMv7处理器中,这条指令时非原子性的。当处理器碰到这条指令时,实际上是执行2条32位的单独存储动作。同样的,任何运行在其他核心的线程都可能会观察到一个“撕裂读(torn write)”。有意思的是,“撕裂读(torn write)”甚至可能会发生在单核设备中:因为系统中断。在2条32位存储指令中间,可能会发生线程上下文的调度切换。这种情况下,当线程从中断中恢复后,将会重新执行一次strd指令。
另外一个例子,是发生在大家熟知的x86平台上。一个32位的mov指令只有在内存操作数是自然对齐的情况下才是原子性的!其他情况下是非原子性的。换句话说,一个32位的整形,只有它的内存地址是4的整数倍情况下,原子性才能有保证。Mintomic有另一个测试用例test_load_store_32_fail,可以验证此种情况。在写本文的时候(译注:2013年6月),这个测试用例在x86平台上总是成功的。但是如果你将测试变量sharedInt的地址强制修改为非对齐的内存地址,那么测试结果将会失败。在我的Core 2 Quad Q6600机器上,如果sharedInt是跨越了单条缓存行界限(crosses a cache line boundary),那么测试就会失败。
// Force sharedInt to cross a cache line boundary:
#pragma pack(2)
MINT_DECL_ALIGNED(static struct, 64)
{
char padding[62];
mint_atomic32_t sharedInt;
}
g_wrapper;
对于特定处理的情况已经说的够多了,接下来看看在C/C++语言层面的原子性。
所有的C/C++操作都假设是非原子性的
在C和C++中,每一个操作都被假定为非原子性的,即使是普通的32位整形赋值。除非编译器或硬件厂商有特殊说明。
uint32_t foo = 0;
void storeFoo()
{
foo = 0x80286;
}
语言标准中没有提及关于以上情况的原子性。也许整形赋值是原子性的,也许不是。因为非原子性的操作不做任何保证,所以在C中定义普通的整形赋值是非原子性的。
在实践中,我们通常比这更了解我们的目标平台。例如,大家都知道,在所有现代的 x86、x64、Itanium、SPARC、ARM 和 PowerPC 处理器上,只要目标变量自然对齐,普通的 32 位整数赋值就是原子操作。你可以通过查阅处理器手册和/或编译器文档来验证这一点。在游戏行业,我可以告诉你,许多 32 位整数赋值操作都依赖于这个特定的保证。
尽管如此,在编写真正可移植的 C 和 C++ 代码时,一直有一种传统,假装我们对平台的了解仅限于语言标准所告诉我们的内容。可移植的 C 和 C++ 旨在运行于所有可能的计算设备,无论是过去的、现在的,还是假想的。就个人而言,我喜欢想象一种机器,在这种机器上,内存只能通过先将其混合才能进行更改:

在这样的机器上,你绝对不想在进行普通赋值的同时执行并发读取;否则你可能会读取到一个完全随机的值。
在C++11中,终于有了一种方法可以执行真正可移植的原子加载和存储:C++11原子库。使用C++11原子库执行的原子加载和存储甚至可以在上述虚拟计算机上运行——即使这意味着C++11原子库必须在后台悄悄地锁定一个互斥锁来保证每个操作是原子的。此外,还有我上个月发布的Mintomic库,虽然它不支持那么多平台,但支持一些较老的编译器,经过手动优化,并且保证是无锁的。
不严格的(Relaxed)原子操作
让我们回到原来的sharedValue例子。我们将会使用Mintomic对其进行重写。这样在Mintomic支持的平台上,所有的操作都是原子性的了。首先,必须将sharedValue声明为Mintomic的原子数据类型的一种。
#include <mintomic/mintomic.h>
mint_atomic64_t sharedValue = { 0 };
mint_atomic64_t类型在不同的平台上,保证原子访问都有正确的内存对齐。这很重要。因为在一些平台的编译器中并不做出类似的保证。比如ARM上的和Xcode 3.2.5绑定的GCC4.2版,就不保证普通的uint64_t是8字节对齐的。
在修改sharedValue时,不再调用普通的、非原子的赋值操作,而是调用mint_store_64_relaxed。
void storeValue()
{
mint_store_64_relaxed(&sharedValue, 0x100000002);
}
同样的,在读取sharedValue变量的值时,我们使用mint_load_64_relaxed。
uint64_t loadValue()
{
return mint_load_64_relaxed(&sharedValue);
}
使用C++11的术语来说,上述方法是无数据竞争(data race-free)的。在执行并发操作时,绝对不可能存在“撕裂读”或“撕裂写”。不管是运行在ARMv6/ARMv7,x86,x64或PowerPC。下面是C++11的版本:
#include <atomic>
std::atomic<uint64_t> sharedValue(0);
void storeValue()
{
sharedValue.store(0x100000002, std::memory_order_relaxed);
}
uint64_t loadValue()
{
return sharedValue.load(std::memory_order_relaxed);
}
你可能注意到,不管Mintomic还是C++11版本的代码都使用了relaxed语义的原子操作,也就是带有_relaxed后缀的内存序列参数。
特别地,关于relaxed语义的原子操作,在此原子操作的之前或者之后的指令都可能被影响,也就是被乱序执行。可能是因为编译器指令乱序或者处理器的指令乱序。编译器可能还是在重复的relaxed原子操作上做一些优化,就像在非原子性的操作上一样。在所有的情况下,这个操作都是原子操作。
当并发地操作共享变量,一贯地使用C++11 atomic库或者Mintomic是个好习惯,即使是你知道在你所针对的平台上,普通的读或写操作已经是原子操作。一个atomic库的方法可以起到一个提示作用,提示这个变量是并发访问的。
总结
原子加载和存储操作在处理器级别上确保对共享变量的读取或写入是不可分割的,其他线程无法在操作过程中观察到半完成的状态。而非原子操作则可能在多个CPU指令之间被打断,导致数据不一致或“撕裂”的读写。
在C/C++语言级别,原子操作通过C++11的std::atomic库提供,确保在多线程环境中对共享变量的操作是线程安全的。与此相比,非原子操作则没有这种保证,可能会导致数据竞争和未定义行为,尤其在并发写入时。